Battle: Play, Node.js, Flask, uwsgi, gevent, gunicorn, Torando and MongoDB
A few benchmarks on popular web frameworks you would consider to build a REST API.
Also a good occasion to talk about an event-driven model versus a more classical threaded model
This first part is an explanation of general programming concepts and might be skipped if you are not interested or if you are already well aware of these notions.
#Introduction -should I thread?-
First, ask yourself these questions when creating your application.
Is my application CPU bound ? Will it mainly do complex calculations (maths, images processing, encoding, etc …) ?
Is my application IO bound ? Will it mainly call a database, read or write files to the disk, making network calls?
Let’s start with a computer with one CPU and one core and run your application.
If your application is CPU bound, then your CPU will be busy doing a useful job and there is not much you can do other than waiting for it to finish or scale with a more powerful CPU or another machine.
But if your application is IO bound, in a lot of cases (we will see when next), your application will be stuck as well even if it is not really doing anything else than waiting for your network or disk to provide some input.
##So how could my application server more requests?
Let’s assume you are in the first case -CPU bound-
The traditional approach would be to have a most efficient CPU, in a simplified model, a CPU running at a higher frequency, so finishing its job faster. Well there are some technology limitations in how high the frequency can go, so nowadays we have CPUs with multiple cores.
To go faster, one strategy is to send smaller amount of work to each of the core and then gather the results. In a web application, if one core is busy, we could still process other requests with other cores.
###Let’s move back to our web application and introduce the concept of processes and threads
When starting your application, the operating system will start a process to isolate it from other applications running at the same time in the OS. It will allocate a certain amount of memory to it and a port on which you can access the application. Now we need a way to benefit from the multiple cores that we have nowadays in our computers (even the cheapest regular desktop computer you can buy today).
The best way to achieve that is through threads. You can view a thread as a lightweight process. Threads are created within the application and share the memory and state allocated to the process -which is a nice feature as we will see later- They are cheaper to create/dispose than processes but are also a bit more dangerous than processes. One thread can make your whole application crashes (the process, therefore all the threads) whereas processes run in isolation. In addition as they share memory and state, you can access the same objects from different threads and run into bad situations like deadlocks. This generally results from bad coding, so it can be fixed. Creating processes instead of threads is more expensive in time and resource (memory usage). Moreover there is no memory sharing, so it is not well suited for sessions based application in which you will store session primarily in memory. Stateless applications as a simple REST API do not have this concern.
###What should be my ideal configuration?
If your CPU has N cores, then ideally you would have one process with N threads, each of the threads running on one core and always doing something useful, meaning not waiting for IO.
This ideal solution is not achievable in all programming languages. A few are mentioned here as they will be used next for the benchmarks. JVM languages (Java, Scala, Groovy, …) : Run 1 process with N threads Python (most common implementation is CPython: It is not possible to run more than one thread at the same time, so you need to create N processes. A lot of times threads are blocked/waiting on IO, in this case it is still a good idea to have multiple threads within one process (refer to threads advantages in previous section). Application server will usually run a pre-forked model with a parent process creating nbCpu child processes. So usually it is possible to share memory for the server libs (like Flask lib) Node.js: Will run one thread per process, so create N processes as well
###What is a simple API or application usually doing?
Connecting to a database or reading from disk!
At this point, I want to clarify some terms and concepts you will see in the rest of the article:
###Threaded model
Most of the applications you will find in the wild are based on this model. Remember that if your core is doing something useful (not waiting for IO), there is not much you can do about it, but this is not the most common case. A lot of time, your thread will be reading from a socket or from disk and it will be waiting for the input to be available. You cannot do anything else with your thread because it is blocked doing that. If you have another thread ready -let’s say from another request-, the CPU scheduler will switch to this thread and run it, actually doing something interesting. This is the classic model and formerly the most popular one because it is simple to understand and easy to code against; programming languages also exposed apis to read/write in a blocking way more than they did in a non blocking fashion. Yet this model has flaws when you want to handle thousands of concurrent requests.
Plus: Well implemented in most languages, easy to understand and code against - synchronous -
Minus: It does not scale well. Each thread has a stack trace for execution and this consumes memory (1MB per thread on a Linux JVM 64 bits), even worse if we are talking about processes instead of threads. In addition the CPU scheduler introduces an overhead when switching a lot between so many threads, meaning that a high fraction of the CPU availability will be used for the scheduler. Have to be careful about shared variables (mutex, synchronization, deadlocks, …)
###Event model
In an application mostly IO bound (does not apply if highly CPU bound), we just saw that we spent most of our time waiting/blocked. This model only runs a single thread but it is crucial that we do not run any blocking operations in this thread. The thread only executes useful code and listen to events. Instead of blocking when reading a socket, it will usually register a callback to be executed when the socket is ready. Ideally reading the socket is done through non blocking systems operations -epoll, kqueue, select- .
Plus: scale very well, low memory usage, no cpu scheduler switch
Minus: Harder to code against, usually lot of callbacks and nested code structure, often associated with asynchronous coding, harder to debug or trace execution, does not fit well in all use cases
###Synchronous code
The code will be executed sequentially as you see it. The thread waits for a statement to complete -even if blocking- before executing the next statement.
###Asynchronous code
The code will NOT be executed in the order you see. The thread will execute asynchronous code (as sending an async HTTP request) and move on before receiving the response). As you eventually want to do something with the response, this style is usually associated with callbacks. You register a callback to be executed when you receive a notification that you received the response. The other way of dealing with async -instead of callbacks- is to use Futures or Promises which telles you you will get the result or an error at some point in the future.
###Blocking/Non blocking
This reflects the status of your thread. You may achieve non blocking by different mechanisms as being notified (event) or by polling a status on a given interval. Note that even if your thread is blocked, you may have non blocking code block, if you run your blocked thread code in another thread and do not wait for the response in the current thread.
People usually mixes async/non blocking IO, which is fine, usually async is associated with callbacks being registered while you can do a non blocking IO by calling an non blocking socket which would just give you an error instead of wait if data is not there. Also note that you can have blocking code without blocking I/O. In a multithreaded environement, if you have two threads competing for the same shared resource and the code is synchronized, one thread will be blocked until the other one release the resource.
Note also that a very heavy CPU bound application can lead to blocking application. That’s why we hear that frameworks like Node.js are not suited for such heavy work. If you do not run multiple processes (with the cluster module for instance), you will run 1 process and 1 thread. If your thread is busy doing a long task, the server cannot process any other request. If you don’t mind that your heavy background job will take 40 sec instead of 30 sec, you can still run other threads just to serve requests. Imagine serving request which would take 5ms and almost no CPU but you cannot serve any of them because of the heavy job, that’s annoying. With multiple threads or processes, the CPU will switch from time to time to the other threads to serve requests.
#Benchmarks Purpose of the test is to get a single document from a database (MongoDB) and send it to the client.
A lot of systems move to a n-tiers model with one tier servicing as a content source API. Usually the new standard for this system is to connect to various other back-end systems and provide a HTTP api to the clients (used to be SOAP, now flavour is more REST). As a result, this system often depends mainly on I/O and does not do crazy calculations => event driven is an appropriate fit! Therefore, we will test a web application waiting on database calls.
Many clients will create requests at the same time. The goal is not to test and stress MongoDB but rather the web frameworks. As a consequence, the database will only contains one simple record.
We will test returning a small document (only one field) and a larger document (hundreds of fields).
##Configuration
| Client | Server application | Server database |
|---|---|---|
| Intel i5-2500K | AMD-FX 8320 8 cores (VM of 4 cores) | AMD-FX 8320 8 cores (VM of 3 cores) |
| 8GB Ram | 4GB Ram | 2GB Ran |
| 128 Gb SSD | 128 Gb SSD | 128 Gb SSD |
| Ubuntu 14.04 server | Ubuntu 14.04 server | Ubuntu 14.04 server |
I first tested JMeter which has nice graphs and metrics. Yet it is heavy and threaded. So creating more clients use more threads. It resulted that JMeter was a bottleneck (100% CPU use) so I moved to wrk which is a better fit for pure load tests: https://github.com/wg/wrk
JMeter is nice if you want to build tests scenarios.
###Frameworks tested:
- Flask, python (v2.7.6) : on uwsgi, PyMongo driver -threaded model-
- Flask, python : on uwsgi (2.0.4) with gevent(1.0.1), PyMongo driver -event model via patching-
- Flask, python : on Gunicorn (v18.0) with gevent, PyMongo driver -event model via patching-
- Tornado, python : Motor mongo driver -event model-
- Node.js (v0.10.25) , javascript V8: mongo-native driver, Event model
- Play! (v2.2.3, openJDK 1.7.0_55) scala: ReactiveMongo, Event model
###Non blocking libs
In an event driven framework like Node.js, all the libs you will usually find are asynchronous as it is the design of Node.js, so you do not have to think too much. When using Play! (Java or Scala) or Tornado (Reactive frameworks), you will also leverage Java and Python and therefore you can find many libraries which are blocking. Always try to find async non blocking libraries.
For Play! and Mongo when working with Scala, you could use the following:
- Java mongo driver
- Casbah (scala mongo driver)
- Salat (layer on top of Casbah)
- Reactive Mongo
On these 4 choices, only Reactive Mongo is a good choice as it the only one which is not blocking. Play! will only start (configurable) nbCpus threads to serve requests.
####So what to do if I do not find any non blocking libs?
Well your best solution is to execute blocking code in another thread pool, so you do not impact the pool serving requests. You usually want this thread pool to be larger (in the hundreds , and you will increase the number with the time your threads will block and the frequency/concurrency of use of these threads)
##Setting up the VMs
We use Oracle VirtualBox to create the VMs.
###On Mongo VM, install:
Just follow instructions here:
http://docs.mongodb.org/manual/tutorial/install-mongodb-on-linux/
Create a db, collection and document:
mongo@mongo:~/mongodb/mongodb-linux-x86_64-2.6.1/bin$ ./mongo
MongoDB shell version: 2.6.1
connecting to: test
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
http://docs.mongodb.org/
Questions? Try the support group
http://groups.google.com/group/mongodb-user
> show dbs
admin (empty)
local 0.031GB
> use articles
switched to db articles
> db.articles.insert({'canonicalUrl':'http://foo.com'})
WriteResult({ "nInserted" : 1 })Increase the number of open descriptors:
sudo -i
ulimit -n 100000
./mongod###On Server VM: install: Install git: here
#Clone git repo:
git clone https://github.com/heichwald/benchmark_web_frameworks
#Python pip:
sudo apt-get install python-pip
#Python virtualenv:
sudo pip install virtualenv
#Python frameworks:
sudo apt-get install build-essential python python-dev
sudo pip install uwsgi
sudo pip install gunicorn
sudo pip install gevent
sudo pip install tornado
#Java:
sudo apt-get install openjdk-7-jdk
#Play:
wget http://downloads.typesafe.com/play/2.2.3/play-2.2.3.zip
#unzip it. Then create symlink.
sudo ln -s ~/play-2.2.3/play /usr/bin/play
#Node.js:
sudo apt-get install nodejs
sudo ln -s /usr/bin/nodejs /usr/bin/node`
sudo apt-get install npm
sudo -i
ulimit -n 100000Execute server as root
#Tests
As an introduction, I want to emphasize again how careful you have to be if you choose the threaded model.
After installing the dependencies above for Flask and uwsgi, you could run:
uwsgi --processes 1 --threads 1 --http-socket :5000 --wsgi-file ~/benchmarks_web_frameworks/flask/app.py --callable app -H ~/benchmarks_web_frameworks/flask/venvThis will serve 1 request at a time. If your database call is 10ms, then you will serve sequentially 1000/10=100 requests per second.
To see this behavior explicitly, you can test the /sleep endpoint. by sleeping 1 sec, we simulate a blocking database call which would take 1sec.
##Intro
###We run 1 client
Running 5s test @ http://192.168.0.12:5000/sleep
1 threads and 1 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.00s 0.00us 1.00s 100.00%
Req/Sec 0.00 0.00 0.00 100.00%
5 requests in 5.02s, 390.00B read
Socket errors: connect 0, read 4, write 0, timeout 0
Requests/sec: 1.00
Transfer/sec: 77.67B
###We run 2 clients but the throughput is still the same
Running 5s test @ http://192.168.0.12:5000/sleep
1 threads and 2 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.01s 0.00us 2.01s 100.00%
Req/Sec 0.00 0.00 0.00 100.00%
5 requests in 5.02s, 390.00B read
Socket errors: connect 0, read 4, write 0, timeout 1
Requests/sec: 1.00
Transfer/sec: 77.68B
###Now if we run 2 threads:
uwsgi --processes 1 --threads 2 --http-socket :5000 --wsgi-file ~/benchmarks_web_frameworks/flask/app.py --callable app -H ~/benchmarks_web_frameworks/flask/venvRunning 5s test @ http://192.168.0.12:5000/sleep
1 threads and 2 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.00s 0.00us 1.00s 100.00%
Req/Sec 1.00 0.00 1.00 100.00%
9 requests in 5.03s, 702.00B read
Socket errors: connect 0, read 8, write 0, timeout 0
Requests/sec: 1.79
Transfer/sec: 139.59B
Not that running two processes will work too but the overhead is larger with processes than threads. You can run 1000 threads (you cannot run 1000 processes -cpu, memory-)
##Test Flask
cd #{to the flask directory}
virtualenv venv
. venv/bin/activate
pip install -r requirements.txt Adjust ip in app.py to your mongo VM ip (I use bridge network adapter in VM, so that my VM has an IP visible on the network)
###Flask + uwsgi -threaded model, it is the default-
#4 processes is optimal for python as we have 4 cores, we should adjust threads to be equal to the number of concurrent requests / 4. Above, we would serve 4 concurrent requests.
uwsgi --processes 4 --threads 1 --http-socket :5000 --wsgi-file ~/benchmarks_web_frameworks/flask/app.py --uid testflask --callable app -H ~/benchmarks_web_frameworks/flask/venv One drawback of using multiple processes is using more memory and also the multiplication of Mongo clients -one pool per process- and thus it is harder to configure properly the connection pool because you have to know the number of processes that you will run in production.
###Flask + uwsgi + gevent
Gevent add an event model (non blocking) and provides a synchronous api on top of it (pretty unusual and pretty cool), so you do not have to write callbacks.
It will patch all I/O operations so they won’t block anymore. So this means that we can run the process with only one thread.
Gevent in uwsgi has an option called asynccores. Actually it has nothing to do with actual cpu cores or threads as only one thread runs but it allows to specify the number of max concurrent requests allowed.
Indeed each additional concurrent request will result in a representation of the request context and state in memory and thus additional memory consumed; obviously you can specify a very high number and memory will only be consumed per the actual concurrent requests.
Uncomment the following line in app.py
from gevent import monkey; monkey.patch_all()And increase the number of connections in the pool to 500.
If you plan to support 1000 concurrent users and you would run 4 processes, you may lower the connection pool in each client to 250.
Here we specify a max of 5000 concurrent request (async cores). Note that we run a single process and a single thread !
uwsgi --gevent 5000 --http-socket :5000 --wsgi-file ~/benchmarks_web_frameworks/flask/app.py --callable app -H ~/benchmarks_web_frameworks/flask/venvWe may also increase the number of processes.
uwsgi --processes 4 --gevent 5000 --http-socket :5000 --wsgi-file ~/benchmarks_web_frameworks/flask/app.py --callable app -H ~/benchmarks_web_frameworks/flask/venv###Flask + gunicorn + gevent
Gunicorn by default uses sync workers (worker means process). It is not possible to specify threads.
As a consequence for us, it is almost mandatory to run it with an async framework like gevent.
So leave the gevent patching uncommented in app.py, go the app folder and and run:
#5000 max concurrent requests using 4 processes.
. venv/bin/activate
gunicorn -b :5000 -k gevent -w 4 --worker-connections 5000 app:appNot that usually they advice to run python frameworks with 2*nbCpu+1 processes, so in our case 9, yet as we only do non blocking I/O, it does not bring additional perf. It would, if we would have some blocking calls.
##Test Node
#Install dependencies:
npm install
#Node is easy to start
node appNode, as python runs 1 thread in 1 process, so we use cluster module which will pre-fork nbCpu processes for us. Cluster module is defined in the code of the application. Same remarks for pool size as python apply.
##Test Tornado The idea behind Tornado is the same as with Node. It does not run under uwsgi, as uwsgi does not support async calls.
python app.py##Test Play
play start It will download required dependencies. Play starts one process and uses nbCpu threads to handle requests.
##Client
Install wrk: here git clone or download the zip.
#Install dependencies :
sudo apt-get install libssl-dev
#Compile:
make
#To test 200 concurrent connections for 30 sec, start with:
./wrk -t1 -c200 -d30s -http://192.168.0.12/mongo
#We do not need more than 1 thread here.##Results
I ensured to replay tests at least 3 times for variance and also ensured that I had enough threads*processes to cover for the nb of requests in the threaded model.
For play, I used 6000 connections in the Mongo pool configuration.
For python and node, I used 6000/4 processes = 1500 in the pool configuration
Be sure to check your ulimit -n settings
Max load is 5000 concurrent requests.
###First test is a with a very small json document (only 1 field)
Successful requests

Failed requests
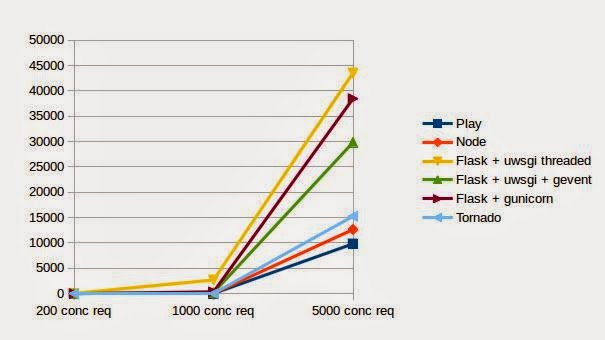
Conclusion: Play! is the fastest, threaded model with uwsgi is the slowest and the one throwing the most errors.
###Second test is a with a big json document (src on github)
Successful requests

Failed requests
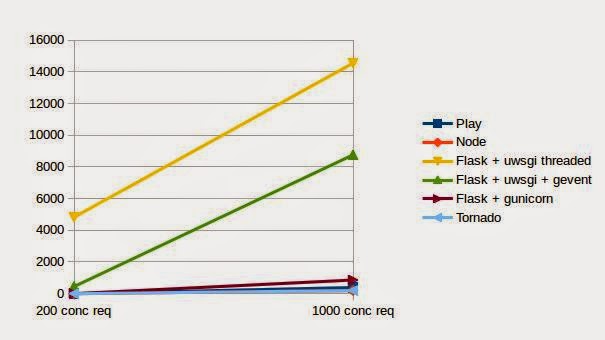
Conclusion: Looks like Node is really fast as de-serialization of BSON-> JSON via Javascript must be very efficient compared to the other languages.
Event-driven frameworks are fast. Gunicorn is a better choice than uwsgi.
##Full report:
###Small document
####200 clients/concurrent requests:
Play:
test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 57.07ms 73.09ms 1.18s 87.40%
Req/Sec 3.52k 636.42 5.50k 71.55%
104786 requests in 30.00s, 16.09MB read
Requests/sec: 3492.87
Transfer/sec: 549.17KB
Node:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 69.71ms 96.14ms 766.52ms 95.80%
Req/Sec 2.95k 191.85 3.41k 69.70%
87592 requests in 30.00s, 22.14MB read
Requests/sec: 2919.74
Transfer/sec: 755.60KB
Flask + UWSGI threaded:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 159.40ms 133.66ms 901.64ms 75.38%
Req/Sec 828.39 71.71 0.92k 72.73%
24712 requests in 30.00s, 3.72MB read
Socket errors: connect 0, read 24709, write 0, timeout 45
Requests/sec: 823.69
Transfer/sec: 127.09KB
Flask + UWSGI + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 91.16ms 21.97ms 316.48ms 91.30%
Req/Sec 1.54k 62.07 1.67k 75.93%
46240 requests in 30.00s, 6.97MB read
Socket errors: connect 0, read 46223, write 0, timeout 0
Requests/sec: 1541.34
Transfer/sec: 237.82KB
Flask + Gunicorn + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 73.31ms 59.08ms 537.16ms 80.88%
Req/Sec 2.69k 164.36 2.88k 86.25%
80353 requests in 30.00s, 18.54MB read
Requests/sec: 2678.43
Transfer/sec: 632.99KB
Tornado + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 68.19ms 28.91ms 167.48ms 73.29%
Req/Sec 2.91k 136.80 3.26k 64.49%
86753 requests in 30.00s, 22.67MB read
Requests/sec: 2891.78
Transfer/sec: 773.78KB
####1000 clients/concurrent requests:
Play:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 195.40ms 78.51ms 2.42s 92.69%
Req/Sec 5.15k 539.84 6.14k 62.50%
152946 requests in 30.00s, 23.48MB read
Requests/sec: 5098.15
Transfer/sec: 801.57KB
Node:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 352.00ms 215.41ms 1.96s 79.08%
Req/Sec 2.83k 172.33 3.24k 75.00%
84316 requests in 30.00s, 21.31MB read
Requests/sec: 2810.50
Transfer/sec: 727.33KB
Flask + UWSGI threaded:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 889.14ms 1.62s 24.14s 97.30%
Req/Sec 786.79 116.25 1.09k 69.70%
23529 requests in 30.00s, 3.55MB read
Socket errors: connect 0, read 23527, write 0, timeout 2693
Requests/sec: 784.29
Transfer/sec: 121.01KB
Flask + UWSGI + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 433.91ms 227.04ms 4.08s 93.26%
Req/Sec 1.55k 88.75 1.74k 59.46%
46356 requests in 30.00s, 6.98MB read
Socket errors: connect 0, read 46355, write 0, timeout 193
Requests/sec: 1545.13
Transfer/sec: 238.41KB
Flask + Gunicorn + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 391.82ms 352.81ms 8.90s 91.60%
Req/Sec 2.48k 272.07 3.11k 71.88%
74063 requests in 30.00s, 17.09MB read
Socket errors: connect 0, read 0, write 0, timeout 345
Requests/sec: 2468.73
Transfer/sec: 583.43KB
Tornado + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 377.50ms 211.26ms 1.79s 84.83%
Req/Sec 2.59k 490.37 3.77k 73.26%
77651 requests in 30.02s, 20.29MB read
Requests/sec: 2586.83
Transfer/sec: 692.18KB
####5000 clients/concurrent requests:
Play:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 5000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 784.53ms 1.00s 22.79s 96.99%
Req/Sec 6.01k 0.97k 7.69k 71.43%
177443 requests in 30.00s, 27.24MB read
Socket errors: connect 0, read 369, write 0, timeout 9831
Requests/sec: 5914.00
Transfer/sec: 0.91MB
Node:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 5000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.90s 1.15s 6.71s 90.60%
Req/Sec 2.43k 521.25 3.42k 68.97%
70955 requests in 30.00s, 17.93MB read
Socket errors: connect 0, read 0, write 0, timeout 12651
Requests/sec: 2365.01
Transfer/sec: 612.04KB
Flask + UWSGI threaded:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 5000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 7.26s 9.86s 26.35s 79.21%
Req/Sec 0.87k 158.51 1.21k 74.19%
25560 requests in 30.02s, 3.85MB read
Socket errors: connect 0, read 26076, write 0, timeout 43560
Requests/sec: 851.37
Transfer/sec: 131.36KB
Flask + UWSGI + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 5000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.43s 2.08s 26.14s 93.81%
Req/Sec 1.58k 92.50 1.78k 72.73%
46912 requests in 30.00s, 7.07MB read
Socket errors: connect 0, read 46903, write 0, timeout 29852
Requests/sec: 1563.52
Transfer/sec: 241.25KB
Flask + Gunicorn + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 5000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.20s 2.13s 27.03s 96.46%
Req/Sec 2.16k 242.02 2.56k 69.44%
64328 requests in 30.00s, 14.85MB read
Socket errors: connect 0, read 388, write 0, timeout 38478
Requests/sec: 2144.11
Transfer/sec: 506.71KB
Just to show you that more processes don't improve,
next are tests with 9 processes for gunicorn
W/o gevent
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 433.07ms 2.85s 28.31s 98.93%
Req/Sec 1.34k 533.32 2.00k 70.44%
40363 requests in 30.00s, 9.12MB read
Socket errors: connect 0, read 0, write 0, timeout 202
Requests/sec: 1345.40
Transfer/sec: 311.39KB
Here it is not too bad, because db call is on the same machine, so smaller than 1ms; it would be awful if db is slow or busy or network latency is high.
With gevent
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 76.28ms 98.70ms 1.88s 88.86%
Req/Sec 2.59k 92.71 2.77k 66.23%
77420 requests in 30.00s, 17.87MB read
Requests/sec: 2580.67
Transfer/sec: 609.88KB
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 400.74ms 284.32ms 5.32s 92.30%
Req/Sec 2.50k 92.26 2.66k 62.50%
74142 requests in 30.00s, 17.11MB read
Socket errors: connect 0, read 0, write 0, timeout 67
Requests/sec: 2471.36
Transfer/sec: 584.05KB
Tornado + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 5000 connections
` Thread Stats Avg Stdev Max +/- Stdev
Latency 2.33s 1.39s 19.26s 90.36%
Req/Sec 2.15k 278.71 2.46k 62.50%
61850 requests in 30.00s, 16.16MB read
Socket errors: connect 0, read 0, write 0, timeout 15260
Requests/sec: 2061.52
Transfer/sec: 551.62KB
###Big document
####200 clients/concurrent requests:
Play:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 254.29ms 262.76ms 2.09s 92.59%
Req/Sec 1.05k 364.50 1.58k 65.52%
31045 requests in 30.00s, 179.13MB read
Requests/sec: 1034.84
Transfer/sec: 5.97MB
Node:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 138.11ms 89.99ms 594.72ms 77.12%
Req/Sec 1.44k 79.86 1.62k 69.70%
42899 requests in 30.00s, 345.38MB read
Requests/sec: 1429.96
Transfer/sec: 11.51MB
Flask + UWSGI threaded:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 604.89ms 866.90ms 5.74s 88.15%
Req/Sec 277.74 89.55 440.00 71.43%
8207 requests in 30.00s, 24.25MB read
Socket errors: connect 0, read 8722, write 0, timeout 329
Non-2xx or 3xx responses: 4498
Requests/sec: 273.56
Transfer/sec: 827.60KB
Flask + UWSGI + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 223.19ms 744.86ms 26.40s 98.98%
Req/Sec 628.22 24.90 678.00 68.75%
18811 requests in 30.00s, 114.81MB read
Socket errors: connect 0, read 18810, write 0, timeout 447
Requests/sec: 627.02
Transfer/sec: 3.83MB
Flask + Gunicorn + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 316.08ms 112.43ms 807.73ms 69.39%
Req/Sec 637.83 25.89 698.00 75.61%
19108 requests in 30.00s, 118.16MB read
Requests/sec: 636.93
Transfer/sec: 3.94MB
Tornado + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 200 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 240.82ms 145.22ms 818.39ms 81.85%
Req/Sec 846.31 81.98 1.04k 63.79%
25263 requests in 30.00s, 156.99MB read
Requests/sec: 842.10
Transfer/sec: 5.23MB
####1000 clients/concurrent requests:
Play:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 857.45ms 589.91ms 15.82s 85.86%
Req/Sec 1.12k 170.53 1.50k 72.09%
33462 requests in 30.00s, 193.08MB read
Socket errors: connect 0, read 195, write 0, timeout 387
Requests/sec: 1115.38
Transfer/sec: 6.44MB
Node:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 740.09ms 424.49ms 3.88s 74.38%
Req/Sec 1.36k 74.50 1.54k 58.82%
40379 requests in 30.00s, 325.09MB read
Socket errors: connect 0, read 0, write 0, timeout 197
Requests/sec: 1345.88
Transfer/sec: 10.84MB
Flask + UWSGI threaded:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.25s 4.73s 13.16s 82.15%
Req/Sec 227.03 87.62 379.00 60.61%
6856 requests in 30.01s, 14.81MB read
Socket errors: connect 0, read 8355, write 0, timeout 9851
Non-2xx or 3xx responses: 4706
Requests/sec: 228.43
Transfer/sec: 505.14KB
Flask + UWSGI + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 462.35ms 1.44s 27.40s 97.03%
Req/Sec 634.82 34.25 720.00 67.65%
18968 requests in 30.00s, 115.77MB read
Socket errors: connect 0, read 18954, write 0, timeout 8766
Requests/sec: 632.26
Transfer/sec: 3.86MB
Gunicorn + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.48s 643.74ms 5.50s 72.59%
Req/Sec 647.46 35.99 718.00 62.86%
19351 requests in 30.00s, 119.66MB read
Socket errors: connect 0, read 0, write 0, timeout 860
Requests/sec: 645.02
Transfer/sec: 3.99MB
Tornado + gevent:
Running 30s test @ http://192.168.0.12:5000/mongo
1 threads and 1000 connections
` Thread Stats Avg Stdev Max +/- Stdev
Latency 1.13s 580.67ms 3.29s 65.88%
Req/Sec 0.87k 127.90 1.27k 79.31%
25725 requests in 30.01s, 159.86MB read
Socket errors: connect 0, read 0, write 0, timeout 191
Requests/sec: 857.27
Transfer/sec: 5.33MB